GitHub+CircleCI+S3でNoOpsなBlogを構築した
本業の傍ら会社の技術 Blog リニューアルに携わっており、概要を Advent Calendar で「DeNA Engineers' Blog をリニューアルしている話」として書きました。
「DeNA Engineers' Blog をリニューアルしている話」ではコンセプトや進め方を中心に書いたので、この記事でもう少しシステム面を書いておきます。
ついでに会社の引き継ぎ資料にしてしまおうという目論見があります。
About
先の記事の繰り返しになりますが、Blog リニューアルの理由は次の 3 点です。
- もっと活性化してほしい
- 機能追加やシステム更新がつらくなってきた
- オンプレミスでのセルフホスティングをやめたい
従ってそれぞれ改善施策をシステムとしても盛り込んでいます。
もっと活性化してほしい
活性化するためにヒト対ヒトのコミュニケーションはもちろん大事なのですが、Blog 記事執筆やレビューのシステムも世の中でも広く使われている GitHub と CircleCI に寄せることで以下を担保しています。
- Blog 執筆専用にアカウントを申請する必要がない
- 執筆やレビューに際して専用ツールを使う必要がない、好きなエディタで書ける!
- 執筆の過程が透明になり誰でも執筆やレビューに参加できる
- 新しく入社した方もすぐキャッチアップできる
- 会社に興味を持ってくださった社外の方も想像しやすい
- 単純に見た目やデザインが新しい方がうれしい!
最後の「見た目やデザインが新しい方がうれしい」については本記事では触れませんが「DeNA Engineers' Blog をリニューアルしている話」をご覧いただくとデザイナー兼フロントエンドエンジニアの方が作ってくださったかっこいいテーマがちょっと載ってます。
また私の本業が ML Ops で AI システム部という部署に所属しているので部内から要望のあったマルチリンガルや数式の表示にも対応させています。
機能追加やシステム更新がつらくなってきた
もちろん Blog がリニューアルされた後には色々な機能追加が行われるでしょうしシステムの更新も長期では避けられないでしょう。
しかしできる限り機能追加やシステム更新のつらみを減らす工夫をしました。
- システムの大部分を一般的な開発環境と共通化することで"Blog 専用システム"の運用を大幅に削減した
- コンテンツ生成を単一バイナリで完結している Hugo で行うことで使用ライブラリの一部が入手できなくなる等のリスクを低減した
- 原稿自体を Markdown 形式のテキストファイルとして GitHub に保持することで仮に他のシステムに移行する際でもマイグレーションを容易にした
- Website ホスティング部分を完全にマネージドサービスに乗せることで通常の運用をセキュリティアップデートを不要にした。NoOps! 👏
オンプレミスでのセルフホスティングをやめたい
これは言わずもがなですね。
オンプレミスのサーバーどころか OS も Web サーバーも構築していません。
そもそも全社的に全面クラウド移行している最中です。
専任のサーバーサイドエンジニアが張り付けるわけではないので通常時の運用はゼロにしました。
S3 と CloudFront はそれぞれ実質無尽蔵といえる容量とトラフィックへのキャパシティを提供してくれます。
AWS Certificate Manager のおかげで TLS 証明書は自動更新されるので有効期限切れを心配する必要もありません。
Viva! NoOps!! 🎉
Structure
以前の記事に書いた通り、このシステムは以下のコンポーネントで構成されています。
- Static Website Generator としてHugoを使用
- 動的コンテンツはホスティングしない
- 原稿管理はGitHub Enterprise
- CircleCI Enterpriseで記事公開のワークフローを構築
- ホスティングはAmazon S3+Amazon CloudFront
- TLS 証明書はAWS Certificate Managerで発行/管理
- 一部コンテンツを社内に限定公開するためにAWS WAFを併用
- AWS の構成はTerraformで行い手オペはしない
そして以下 3 つの環境(Web サイト)が存在します。
- 公開 Blog
- 現在の https://engineer.dena.jp/ に置き換わるもの
- 社内向け Blog
- 社内からのみアクセスできる Blog で公開 Blog よりも気軽に記事を書くことができる
- レビュー用 Blog
- 公開前にレビューを受けるための Blog
- 記事編集ごとに専用 URL が発行される
このシステムの全体像を図に示します。
また AWS 上のコンポーネントを管理する Terraform のサンプルを以下に公開しました。
サンプルリポジトリ:
mazgi-showcase/2019.04.built-noops-blog-with-github-circleci-s3.provisioning
前提
本記事では世界有数の IaaS(Infrastructure as a Service)ベンダーである AWS 自体やその契約方法、IaC(Infrastructure as Code)やその著名なツールである Terraform 自体について深くは触れません。
しかし本記事を読んでいただく上で最小限必要となる知識や設定については前提として以下に記載します。
Terraform の実行と AWS アクセスキー
Terraform は特別なインストール作業不要でお使いの OS に合わせたバイナリをダウンロードし配置するだけで実行できます。
しかし Terraform も他の多くの OSS ツールと同じく進歩の早いソフトウェアなのでtfenvのような複数の Terraform バージョンを管理できるツールを使うと便利です。
サンプルリポジトリのvariables.tf#L1-L2では AWS のアクセスキー ID とシークレットアクセスキーを空にしています。
|
|
これは Terraform の通常の運用方法で variables.tf ファイルはリポジトリに登録されるため、秘匿すべき情報であるアクセスキー ID やシークレットアクセスキーを書くわけにはいきません。
代わりに variables.tf ファイルと同じ階層に terraform.tfvars ファイルを用意して以下の内容を書いておくと Terraform 実行時に自動で変数が読み込まれます。
|
|
この場合 terraform.tfvars ファイルを誤って Git の管理下に入れてしまわないよう .gitignore に登録しておくことを強く推奨します。
また Terraform 実行時に -var オプションでこれらの変数を指定することもできます。
ただしシェルの履歴に残るので注意してください。
$ terraform apply \
-var 'aws_access_key_id=Xx**\*\*\*\***\*\***\*\*\*\***' \
-var 'aws_secret_access_key=Zz**\*\*\*\***\*\***\*\*\*\***\*\***\*\*\*\***\*\***\*\*\*\***'参考:
Input Variables
いずれにしても AWS のアクセスキー ID やシークレットアクセスキーは絶対に公開しないよう、万が一公開してしまった場合はすぐに無効化し不正利用されていないか確認するよう注意してください。
参考:
AWS アクセスキーを管理するためのベストプラクティス
Terraform の State 管理
Terraform は AWS や GCP、Azure その他どの IaaS ベンダーとも独立したHashiCorp主導で開発されている OSS です。
したがって Terraform で構築した AWS 上のシステムの設定情報などは AWS で自動で保存されるわけではありません。
しかしどのような設定を行なったかはどこかに記録しておく必要があります。
Terraform はこれをStateとして管理します。
Terraform の State を管理する方法はいくつかありますが本記事では AWS を Terraform で構成する際に一番多く使われているであろう S3 による管理を想定します。
Terraform の基本設定はサンプルリポジトリの terraform.tf ファイルにまとまっていますが、State の管理方法を定義している箇所はterraform.tf#L7-L11です。
S3 については Blog コンテンツの格納の項で触れますが入れ物を表す bucket としてユニークな名前が指定されている必要があります。
ここで指定した名前の S3 バケットをあらかじめ作っておく必要があります。
|
|
なお本記事上の行番号はサンプルリポジトリ上の行番号と合わせています。
Terraform 実行時の注意
Terraform 実行時にはまず Backend である S3 へのアクセスが検証されます。
検証は前述の terraform.tfvars 読み込みより早く行われるため別の方法で AWS のアクセスキー ID とシークレットアクセスキーを Terraform に知らせる必要があります。
1 つの方法はアクセスキー ID とシークレットアクセスキーを AWS_ACCESS_KEY_ID と AWS_SECRET_ACCESS_KEY という環境変数に入れておくことです。
ただし export AWS_ACCESS_KEY_ID='Xx******************' とシェルで実行した場合は履歴に残ることに注意する必要があります。
もう 1 つの方法は AWS CLI をインストールして aws configure を実行することです。
参考:
Backend Type: s3
Environment Variables
AWS CLI の設定
AWS のリージョン
AWS にせよ他の IaaS にせよ 21 世紀初頭の現代ではまだ物理的な立地を意識する必要があります。
AWS では物理的な立地を「リージョン」として指定できます。
サンプルリポジトリではすべてのコンポーネントを US のバージニア州にある us-east-1 リージョンに配置しています。
この辺だそうです、バージニア。
もし日本国内に配置する場合は東京にある ap-northeast-1 を指定してください。
書き換える箇所はterraform.tf#L10とterraform.tf#L18の 2 箇所です。
3 つの環境
このシステムでは前述の通り以下の 3 つの環境が存在します。
またよくある話ですが .com と .jp で同じコンテンツを表示できるよう考慮しています。
それぞれ実際の URL を例示するわけにはいかないので以下を例として使用します。
- 公開 Blog
- URL(com):
https://example.com - URL(jp):
https://example.jp - コンテンツ S3 バケット:
external-engineers-blog-content
- URL(com):
- 社内向け Blog
- URL(com):
https://internal.example.com - URL(jp):
https://internal.example.jp - コンテンツ S3 バケット:
internal-engineers-blog-content
- URL(com):
- レビュー用 Blog
- URL(com):
https://review.example.com - URL(jp):
https://review.example.jp - コンテンツ S3 バケット:
review-engineers-blog-content
- URL(com):
つまり Blog にアクセスできる TLD(トップレベルドメイン)は .com と .jp の 2 パターンが存在し、各環境の prefix として external, internal, review のいずれかが付く、ただし公開 Blog はちょっと特殊ということですね。
とてもよく似た 3 パターンのコンポーネントを個別に設定したくはないので環境名を列挙して Terraform の機能でループを回せるようにしておきます。
そのためvariables.tf#L12-L18でこのように環境を列挙しておきます。
|
|
これによって length(var.envs)" で要素数を、 element(var.envs, count.index) で N 番目の要素を扱えるようになります。
以降の例では length, element を多用しますが詳細は Terraform ドキュメントのlengthやelementも参照してください。
S3
Amazon S3 はバケットと呼ばれる入れ物にファイルを大量に格納できるオブジェクトストレージサービスです。
外付け HDD のような通常のストレージとの違いの 1 つは WebAPI でオブジェクト(ファイル)の出し入れを行うことです。
今回、HTML, CSS, JavaScript、画像等の Blog コンテンツはこの S3 バケットに配置します。
しかし Audience(Blog を読んでくださる方)が読み取る際には https://example.com のような URL でのみアクセスできるようにします。
これは「オリジンアクセスアイデンティティ」を使用して CDN である CloudFront 経由のアクセスだけ許可することで実現できます。
参考:
オリジンアクセスアイデンティティを使用して Amazon S3 コンテンツへのアクセスを制限する
これらの S3 の構成はs3.website.tfにまとまっています。
順に解説しますが行番号が前後します。
S3 バケット作成
まずは Blog コンテンツを格納する S3 バケットを作ります。
そのコードはs3.website.tf#L48-L62です。
|
|
1 行目:
AWS のリソース"S3 バケット"を website-content という名前で作ることを宣言しています。
なおこの名前は Terraform の管理上使われるものであり URL 等で公開されるわけではないので管理しやすい命名にします。
aws_s3_bucket で検索すると公式ドキュメントにたどり着くことができます。
2 行目:
count という変数に環境名のリスト var.envs の要素数を代入しています。
前述の通り 3 つの環境を作るためにほぼ同じコードを 3 回書きたくはないのでこの要素数を使ってループを回します。
4 行目:
bucket = バケット名 で S3 バケットの名前を指定します。
この S3 バケット名は実際に AWS の S3 バケット名になります。
AWS の仕様で S3 バケットの名前は全世界でユニークにしなければならないので重複しなさそうな命名にします。
Terraform を使って AWS 上にシステムを構築する際の心がけると良い習慣の 1 つは「Terraform の仕様なのか、それとも AWS の仕様なのか」と意識することです。
ここでは Terraform の関数と変数を使って以下の 3 つの S3 バケット名を生成しています。
external-engineers-blog-contentreview-engineers-blog-contentinternal-engineers-blog-content
なお「3 つの環境」の項で書きましたが S3 バケットは環境ごとに 1 つ作成し .com と .jp で共有します。
つまり公開 Blog へのアクセスは .com でアクセスしても .jp でアクセスしても external-engineers-blog-content の内容が表示されます。
(もちろんこれはサンプルなので実際の Blog システムでこの名前の S3 バケットを使っているわけではありません)
5 行目:
S3 バケットのアクセス権を設定します。
Terraform ドキュメントの acl の項をみると acl - (Optional) The canned ACL to apply. Defaults to "private". と書いてあります。
canned ACL の部分がAWS の公式ドキュメントへのリンクになっており、リンクを開くとデフォルトである private のほか public-read, public-read-write などが指定できることがわかります。
このようにして Terraform と AWS 両方のドキュメントを参照しながらコードを書いていきます。
7-10 行目:
今回のように S3 で Web サイトを提供する場合の設定です。
14 行目:
force_destroy を true にしておくと S3 バケット内にオブジェクト(ファイル)が存在しても削除することができます。
Terraform では適用した場合に S3 バケット等が削除と再作成されることがあり、Web サイトのコンテンツが入ったまま S3 バケットを作り直せるよう true に設定しています。
もちろん S3 バケットが作り直されると中身は消えてしまうのですが、今回の例ではコンテンツの元となる原稿は GitHub リポジトリに存在するので復元可能です。
これで Blog コンテンツ用の S3 バケットが作られます。
またs3.website.tf#L66-L80ではアクセスログを蓄積する S3 バケットを作っています。
S3 バケットの権限
Amazon S3 では前述の通り WebAPI を使用してオブジェクトの読み書きを行います。
そして可能な操作をかなり細かく権限設定することができます。
例えば今回は扱いませんが通常のファイルシステムでは困難な「書き込みのみ」といった権限も実現できます。
s3.website.tf#L3-L37が権限設定を表す「S3 バケットポリシー」の定義です。
|
|
では S3 バケットポリシーも各行の意味を簡単に解説します。
1 行目:
S3 バケットの作成では resource を定義するコードでしたが今度は data を定義します。
5-7 行目:
S3 バケットに対して許可する操作を定義しています。
例ではオブジェクト(ファイル)を読み取る s3:GetObject のみを許可していますが複数の操作を列挙することができます。
S3 バケットに対して許可できる操作の一覧はポリシーでのアクセス許可の指定などにあります。
9-11 行目:
今度はこの S3 バケットポリシーの対象となるリソースを列挙しています。
S3 バケットの作成と同じく変数を使って指定することで仮に環境が増えたり変わった場合でもこの部分は変更不要です。
10 行目で aws_s3_bucket.website-content.*.arn の N 番目を取得しています。
これは Terraform の文法で、作成した S3 バケットを示す ID を aws_s3_bucket の website-content の N 番目の要素の ARN として取得しています。
ARN は AWS のリソース表現方法で S3 バケットの 1 つ 1 つ、EC2 での仮想マシンの 1 つ 1 つ、AWS 上のありとあらゆるリソースを一意に示すことができます。
Amazon リソースネーム (ARN) と AWS サービスの名前空間に例がたくさん載っています。
13-17 行目:
プリンシパルとして後ほど出てくる「オリジンアクセスアイデンティティ」を指定しています。
これによって S3 バケットが特定の CloudFront(CDN)からしかアクセスできないよう制限できます。
20-347 行目:
ここでも 4-18 行目と近い設定をしていますが、以下が異なります。
6 行目では s3:GetObject を許可しているのに対し、 22 行目では s3:ListBucket を許可しています。
その操作を 10 行目では S3バケット名/* に許可しているのに対し、 26 行目では S3バケット名 に許可しています。
これによって S3 バケットの各階層ではオブジェクトの一覧を取得でき、各オブジェクトに対しては内容を読めるようになるのですが…まとめても実害ない気がします。
当時かなり細かく権限設定をしたようです 🤔
AWS の考え方としてこのように多くの権限を「ポリシー」として定義し、S3 バケットなどの「リソース」にアタッチすることで有効化します。
s3.website.tf#L39-L44がポリシーを S3 バケットにアタッチする例です。
CloudFront
Amazon CloudFront は AWS の CDN(Contents Delivery Network)で、Akamai や Fastly のようにコンテンツをキャッシュして世界中に高速に配信できるサービスです。
参考:
Amazon CloudFront(グローバルなコンテンツ配信ネットワーク)
しかし今回は S3 と組み合わせることで独自ドメインによる HTTPS での静的コンテンツ配信をサーバーを立てずに実現するために使っています。
Terraform の設定はcloudfront.com.example.tfとcloudfront.jp.example.tfですが、前述の通り同じ構成で .com と .jp を提供するため内容にはほぼ差がないので以降 .com を例に解説します。
ほぼ同じ内容にも関わらずファイルを分けているのは、最初は同じ Web サイトでも往々にして途中からそれぞれの内容が変わっていくためです。
また S3 の項で登場した「オリジンアクセスアイデンティティ」はcloudfront_origin_access_identity.website.tfで設定しています。
内容は aws_cloudfront_origin_access_identity リソースを 3 環境分作っているだけなので割愛します。
オリジンとなる S3 バケットの指定
domain_name で S3 バケットのドメイン名を指定しています。
このドメイン(FQDN)は Blog の URL とは関係なく、S3 バケットを作成した際に AWS 上で自動付与される FQDN です。
またオリジンアクセスアイデンティティの設定を s3_origin_config 内で行なっています。
|
|
DNS エイリアスの指定(CloudFront 側)
CloudFront では「ディストリビューション」を作成することでリクエストを受け付けることができます。
この例では「1 つのディストリビューションは 1 つの Web サイト」と捉えて問題ありません。
そしてディストリビューションごとに 1 つの DNS エイリアスを設定しています。
例えばディストリビューション A には example.com を設定し、ディストリビューション B には review.example.com を設定します。
.com だけ考えても 3 環境あるのですが、以降の箇所だけでこれらを設定しています。
まず再掲しますがvariables.tf#L8-L18で変数として各環境を表すリスト envs と公開 Blog がどの環境かを示す default_env_name の 2 種類を定義しています。
|
|
これらの変数を元にループの中で条件演算子を使って example.com のホスト名を以下の 2 パターンに分岐しています。
- 今扱っている環境が公開 Blog であれば
""(空文字列) - その他の環境であれば
環境名.
|
|
これによって 3 パターンそれぞれの CloudFront ディストリビューションに以下それぞれのドメイン名(FQDN)が DNS エイリアスとして設定されます。
example.com: 指す先の S3 バケットはexternal-engineers-blog-contentreview.example.com: 指す先の S3 バケットはreview-engineers-blog-contentinternal.example.com: 指す先の S3 バケットはinternal-engineers-blog-content
このように変数やループ、分岐を使ってあたかもプログラミングのようにインフラストラクチャーを柔軟に扱えることが Infrastructure as Code(IaC) のメリットです。
ただし分岐しすぎるとインフラストラクチャーが動的になりすぎ実行時の諸条件に左右されてしまいますので注意が必要です。
また Terraform と AWS 両方のドキュメントを確認しながらコードを書いていくことは手間がかかりますが、ほぼ同じ文法で AWS や GCP、Azure など複数の IaaS 上にシステムを構築できることが Terraform のメリットです。
(もし AWS だけを考えるのであればAWS CloudFormationという AWS 製の IaC サービスもあります)
DNS レコードの指定(Route 53 側)
AWS の DNS サービスであるRoute 53の設定も同じファイル内に書いています。
この DNS レコードが CloudFront のディストリビューションを指すため同じファイル内にあった方が見通しが良いという理由です。
公開 Blog の DNS レコードを本当に更新してしまうと今の技術 Blog が置き換わってしまうため公開 Blog の DNS レコードは temporary という仮のホスト名を設定しています。
本記事を試す場合は 85 行目の "temporary." を "" (空文字列)に変えてください。
|
|
本記事では Route 53 自体の解説は行いませんが管理する DNS ゾーンの設定はroute53.com.example.tfとroute53.jp.example.tfにあります。
もしサブドメインを委任した場合でも設定はほぼ変わりません。
コンテンツの TTL 設定
CDN である CloudFront が同じコンテンツを何秒間キャッシュし続けるかを指示する TTL(Time To Live)を設定しています。
後述しますが CloudFront のキャッシュは CircleCI で Blog 記事が執筆されコンテンツが更新された際に明示的に破棄しますので TTL を長めに設定しています。
|
|
TLS 証明書の設定
現代の Web サイトは HTTPS 接続が基本で、経路が暗号化されない HTTP 接続はほとんど使われません。
そして HTTPS で Web サイトを公開するためには TLS(SSL)証明書が必要です。
とても便利なことに今回のように AWS 上で Web サイトを提供する場合には AWS の証明書管理サービスAWS Certificate Manager(ACM)で TLS 証明書を発行することができます。
さらに ACM の TLS 証明書は自動更新されるので毎年毎年 TLS 証明書を購入してアップロードする必要もありません。
TLS 証明書の更新は運用者の引き継ぎなどで漏れやすいことの 1 つです。これも NoOps の大事な要素です。
ここでは ACM の証明書を使う設定を行なっています。
|
|
ACM で TLS 証明書を管理する設定はacm.com.example._.tfとacm.jp.example._.tfにあります。
本記事では各行を挙げることはしませんが「DNS 認証」でドメイン example.com の所有者であることを ACM に検証してもらい TLS 証明書を管理するよう設定しています。
「DNS 認証」は ACM に指定された DNS レコードを DNS サーバーにセットすることでドメインの持ち主であることを証明します。
そのためファイル内には DNS サーバーである Route 53 の設定も含めて見通しを良くしています。
WAF の設定(CloudFront 側)
レビュー用 Blog と社内向け Blog では接続元 IP アドレスによるアクセス制限を行います。
今回はAWS WAF(Web アプリケーションファイアーウォール)でこの制限を実現します。
AWS WAF 自体の設定は後述しますが CloudFront 側から WAF を使う設定は以下の通り web_acl_id を指定するだけです。
公開 Blog では接続元 IP アドレスによる制限は不要なので DNS エイリアスと同じように条件演算子によって公開 Blog だけ AWS WAF を使用しないよう設定しています。
|
|
なお要件により接続元 IP アドレス制限だけではなく他のアクセス制御を組み合わせて使用すべきです。
Lambda@Edge の設定(CloudFront 側)
Audience の S3 バケットへの接続経路を CloudFront 経由に限定した代償として 1 つ不都合が発生します。
それは「 / で終わる path でアクセスしても index.html が返されない」という不都合です。
例えば通常 https://foo.example.com/bar/baz/ にアクセスすると https://foo.example.com/bar/baz/index.html などと同じ内容が表示されます。
これは通常の Web サーバーや S3 バケットで直接静的コンテンツを配信する場合 / で終わる path にアクセスすると index.html (インデックスドキュメント)の path が補完され返されるためです。
しかし今回の構成ではその補完が行われず / で終わる path にアクセスすると想定したコンテンツが表示されません。
そこで CloudFront で任意の関数を実行できるLambda@Edgeを使ってこの不都合を解消します。
参考:
オリジンアクセスアイデンティティを使用して Amazon S3 コンテンツへのアクセスを制限する
できた!S3 オリジンへの直接アクセス制限と、インデックスドキュメント機能を共存させる方法
Lambda@Edge は AWS の Function as a Service(FaaS)であるAWS Lambdaを CloudFront で実行できるようにしたサービスです。
Lambda のような FaaS は JavaScript や Python で書いた関数をアップロードしておき、例えば「S3 バケットにファイルがアップロードされた」等のイベントをトリガーとしてその関数を実行できます。
つまり今回の不都合は Lambda@Edge を使って「Audience が / で終わる URL をリクエストした時」に「リクエスト URL 終端の / を /index.html に書き換える関数」を実行すれば解消できます。
以下が CloudFront でリクエストを受けた際に Lambda@Edge を呼び出す設定です。
Lambda 関数自体は後述します。
|
|
以降で WAF と Lambda@Edge の設定を解説します。
WAF
前述したように今回はAWS WAF(Web アプリケーションファイアーウォール)でレビュー用 Blog と社内向け Blog への接続元 IP アドレスによるアクセス制限を実現します。
WAF 自体の設定はwaf.website.tfです。
接続元 IP アドレスを制限する環境はレビュー用 Blog と社内向け Blog 両方ですが接続元はいずれの Web サイトでも今後変わらない想定なので WAF の設定は 1 つで複数の Web サイト(CloudFront ディストリビューション)に同じ WAF 設定を適用します。
接続許可 IP アドレスリストの定義
そのためにまず接続を許可する IP アドレスを列挙した aws_waf_ipset を定義します。
なお記載した IP アドレスはすべて例示用に予約されているもので実際には使用できません。
参考:
IPv4 Address Blocks Reserved for Documentation
下記のように複数の IP アドレスセットを定義することができます。
|
|
WAF ルールの設定
次に作った IP アドレスリストをルールに組み込みます。
negated を false にセットしているので 2 重否定になり接続元 IP アドレスが IP アドレスリストにマッチすれば適用されるルールになります。
(実際に接続を許可する、あるいは拒否する設定は次の aws_waf_web_acl で指定します。)
|
|
WAF ACL の設定
aws_waf_web_acl で実際のアクセス許可/拒否の設定を行います。
まず default_action を BLOCK に設定し全てのアクセスを拒否します。
次いで rules 内で action を ALLOW に設定し前述のルールを指定します。
|
|
Lambda@Edge
次に末尾 / でアクセスされた際に index.html を補う Lambda@Edge の設定とソースコードを掲載します。
Lambda@Edge ソースコード
ソースコードは JavaScript で実装しておりlambda-sources/redirect-to-index-document/index.jsがすべてです。
内容も正規表現で /$ にマッチしたら /index.html に置き換えるという極めてシンプルな関数です。
JavaScript のソースコードも同じリポジトリに置いているので今後リファクタリングや仕様変更を行なっても Terraform と合わせて変更を管理できます。
また後述しますが Terraform でソースコードファイルを AWS にアップロードして Lambda 関数として登録できるので同じディレクトリツリーにおいておいたほうが便利です。
|
|
Lambda@Edge 向け権限設定
Lambda@Edge を設定する Terraform のコードはlambda.website.tfですが前半で Lambda 関数の実行を許可する権限設定を行なっています。
|
|
1-14 行目で定義した AWS IAM(Identity and Access Management)のポリシーを定義しています。
書式は S3 バケットポリシーと一緒です。
16-24 行目で定義したポリシーを Lambda 関数用のロールにアタッチしています。
Lambda@Edge 向け権限設定
Lambda@Edge を設定する Terraform のコードはlambda.website.tfの後半では前述の JavaScript ソースコードファイルをアップロードし Lambda 関数として登録しています。
|
|
26-30 行目では source_dir で指定したディレクトリを ZIP アーカイブにして output_path に配置するよう設定しています。
32-40 行目の aws_lambda_function リソース定義で Lambda 関数を登録するよう設定しています。
Workflow
レビュー用の Blog は次のスクリーンショットのように Pull Request に Commit を Push するごとに Commit hash を使って専用 URL を発行します。
この URL は社内から GitHub アカウント不要でアクセスできるので、GitHub アカウントを持っていない方でもレビューに参加できます。
ユースケースとして記事内容の法務チェックが必要な場合に Slack やメールに貼り付けてレビューを依頼する等を想定しています。

レビュー URL の仕様
この仕組みでは何回記事内容を更新して Push しても 1 度発行されたレビュー用 URL にアクセスして表示されるコンテンツは変わりません。
これはあえての仕様です。
同じ URL をリロードすることで最新のコンテンツが表示される方が便利に感じますが、メールのような非同期コミュニケーションの場合「昨日の N 時頃の内容でレビューした」「午前中みた内容は OK だったが今見た内容は NG」といった行き違いが発生しがちです。
このような行き違いを Git や Commit hash を普段使っておられない非エンジニアの方とのコミュニケーションで防ぐためには「これが同じであれば内容は同じです」と担保できる「バージョン」あるいは「版数」のようなものが必要です。
しかし記事執筆者が毎回バージョンや版数を振るルールでは漏れが発生しますし負担が大きくなり活性化とは真逆の方向に進んでしまいます。
そこでレビュー専用の URL が都度事項発行され、しかも URL が同じ限り内容が変わらないことが担保されていれば「このアドレス(URL)に対してレビューをお願いします」と依頼することでそのような認識のズレや事故を防ぐことができます。
記事執筆から公開まで
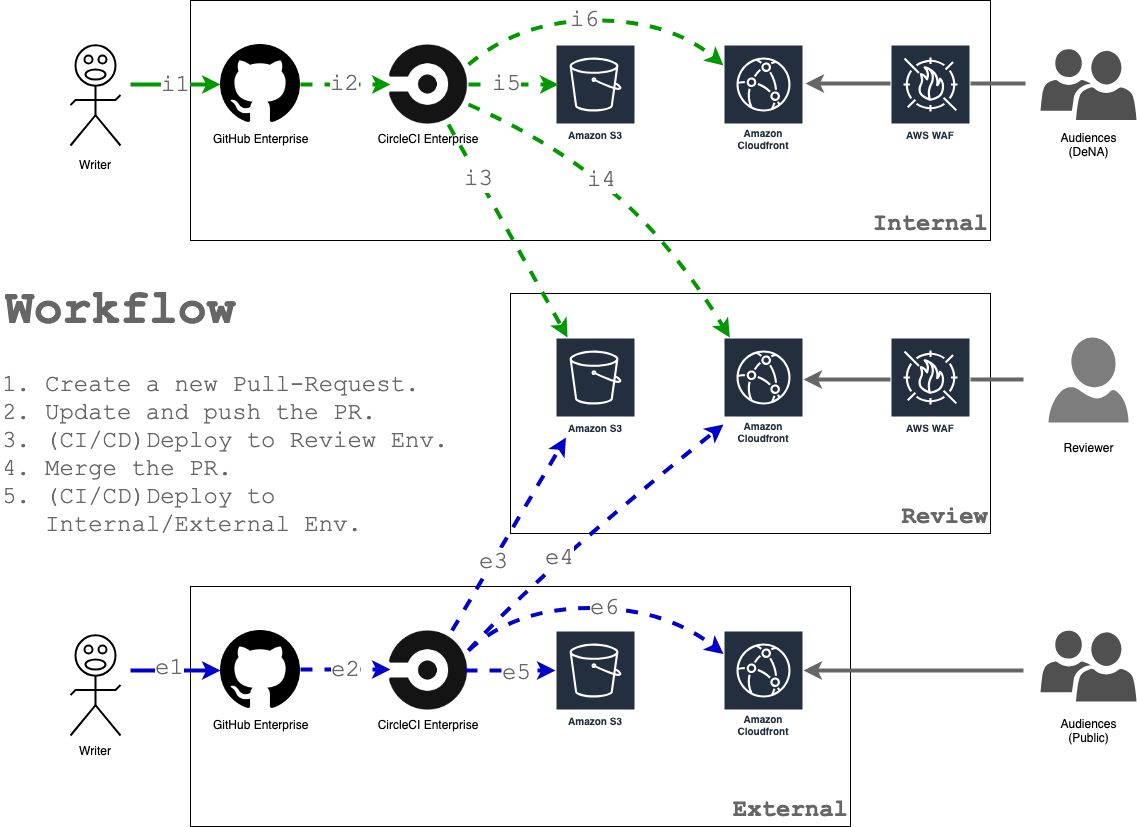
記事執筆から公開までのワークフローと各コンポーネントの関係図を再掲します。
上半分(緑)の矢印が社内向け Blog の執筆、下半分(青)の矢印が公開 Blog の執筆ですが、図の Deploy 先が異なるだけでやっていることは一緒です。
またレビュー用 Blog は公開 Blog と社内向け Blog で共有しています。
下の図では公開 Blog に e1 - e6 , 社内向け Blog に i1 - i6 の番号を振っていますがそれぞれ行なっていることは以下です。
- e1, i1 : GitHub 上の Pull Request に執筆中の Blog 原稿を Push する
- e2, i2 : CircleCI 上で Job が実行されコンテンツの HTML, CSS, JavaScript などが生成される
- コンテンツ内容は Pull Request のブランチの該当 Commit
- レビュー用 URL もこの時に生成され Pull Request コメントとして書き込まれる
- e3, i3 : 生成されたコンテンツがレビュー用 Blog の S3 バケットにアップロードされる
- e4, i4 : レビュー用 Blog の CloudFront キャッシュを削除する
- e5, i5 : 生成されたコンテンツが公開 Blog / 社内向け Blog の S3 バケットにアップロードされる
- e6, i6 : 公開 Blog / 社内向け Blog の CloudFront キャッシュを削除する
もう少し細かいシーケンスを次のサンプルと図で説明します。
サンプルリポジトリはおそらく動作しませんが実際の公開 Blog / 社内向け Blog と概ね近しい構成になっています。
なお公開 Blog と社内向け Blog はそれぞれ独立したリポジトリとして存在していますが、Blog 記事以外の内容はほぼ同じです。
そのため公開するサンプルリポジトリは 1 つです。
サンプルリポジトリ:
mazgi-showcase/2019.04.built-noops-blog-with-github-circleci-s3.example-content
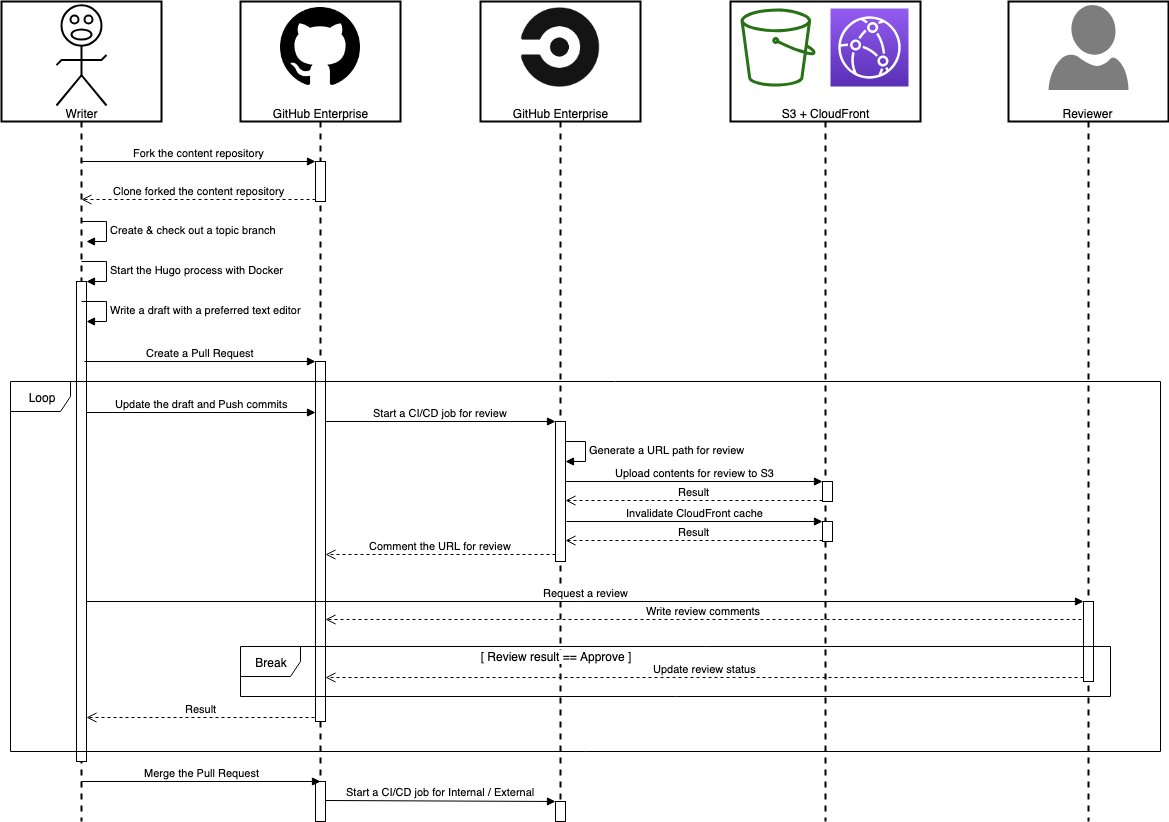
ローカル PC で Hugo を起動する
まず以下のシーケンスでローカル PC 上で Blog の原稿を書ける状態を作ります。
- Fork the content repository
- (中略)
- Write a draft with a preferred text editor
Fork は GitHub の WebUI などから行ってもらいますが、Fork したリポジトリを Clone した後、Blog 原稿の生成まではシェルスクリプトを用意しています。
次の順番で実行することで Hugo バイナリのダウンロード、Hugo の起動、Blog 原稿の生成まで行えます。
どれも中身はシンプルなのでそのままシェルスクリプトを実行するか、あるいは中を読んで同等のことをより自分に合った別の方法で行うかは執筆者に任されています。
また一口に「社内で GitHub アカウントを持っている人」と言っても細かくみると多彩な方がいるのであえて docker-compose 等は使っていません。
(多彩な方といいつつ Windows も Linux も想定できていないのですがそこは Contribute 頼みです)
Pull Request を作ってレビューを受ける
Branch を Push したら WIP(Work In Progress)を明記した上での早めの Pull Request 作成を推奨しています。
図のシーケンスでいう以下の間、Commit を Push するたびにレビュー用 Blog に専用 URL が発行されます。
- Create a Pull Request
- (中略)
- Merge the Pull Request
Pull Request に Commit が Push される度にレビュー用コンテンツを Deploy する部分は以下の CircleCI の設定とシェルスクリプトで行っています。
各種 Token や Credentials の扱いが甘いですが社内ということで現状こんな感じです。
Pull Request を Merge して Blog を公開する
Pull Request が Merge されると今度は master branch が公開 Blog / 社内向け Blog に Deploy されます。
やっていることは.circleci/config.ymlの通りです。
That’s it!
以上、NoOps な Blog の仕組みでした。
特殊なことをやっていないので運用工数を限りなく削減できるのではないかと期待しています。