仕事の振り返り(2019.04)
ここ何年か DeNA という会社で働かせていただいてます。
今月 4 月に異動したこともあり棚卸し的にやってきたことを振り返ってみました。
4 月からは「AI 本部」という組織が新設されすでにこちらで仕事をしています。
3 月末までは「システム本部」所属でした。
きっと数ヶ月もすれば異動までの数年間担っていたことやってきたことは当事者としては書けなくなってしまうでしょうし、今のやっていきたいという気持ちも変わっていくでしょう。
なので今のうちに書き残しておきたいと思いました。
What did I do?
まずこれまで何をしてきたかですが、入社以来やってきたことを一言で表すと「分析基盤と ML(機械学習)基盤の構築運用」です。
そもそもの入社のきっかけは「うちの分析基盤は PB(ペタバイト)のデータあるよ」と言われてほいほいと遊びに行った日に始まります。
誘っていただいた先の部署に知っている方がいる安心感もありマネージャーやらなくても仕事できそうという動機もあり入社させていただく運びとなりました。
配属は発足したばかりの「AI システム部」でした。
部署名の印象とは異なるのですが歴史的にデータマイニングや分析基盤を管掌しており、私が入社した時点でも業務は分析基盤関連の比率が高かったように思います。
いわゆる AI 領域での R&D や PoC は@hamadakoichiさんはじめ少数の方が行なっている、まだそんな時代でした。
そんな状況だったので私の仕事も分析基盤関連から始まり徐々に ML 基盤の仕事が発生しました。
私自身はこの 3 月まで後述するような変遷はありつつも「AI&分析基盤」というチームを預かっていました。
今改めて振り返ると本当に苦労や悩みが多かったですがそれだけ有意義な経験をさせていただいたと感じます。
なんといってもデータ量も利用者規模も私自身が携わった中では最大でしたし、10 年続けて運用され続けている分析基盤も、その分析基盤で PB(ペタバイト)のデータを当たり前に使いこなしている組織は良い意味で衝撃でした。
資料の最後で触れたクラウド化もすでに進み始めており、クラウド移行後がさらに楽しみです。
昨年 2018 年にはTD Tech Talk に登壇のオファーを頂戴し DeNA の分析基盤について紹介させていただきました。
また分析基盤を知っていただく上では他にもいくつか公開されている資料が役立ちます。
もちろん規模が大きく歴史が長いならではの苦労も多くありました。
例えば社内で分析を行うためのクエリエンジンとして近年は Google 社の SaaS である BigQuery を推奨しています。
しかし推奨されているとはいえ BigQuery 以前に Vertica や Hive 向けに書かれたクエリも残っており、それらとの互換性のために Vertica や Hive の関連システムも維持する必要があります。
また 100 台規模のオンプレミスサーバーで構築されている Hadoop クラスタのバージョンアップは毎回お祭りでした。
ただ自分の興味や志向だけに従っていては決して触れることのなかった技術やその技術を活かす設計に正面から取り組む機会はそうそう得られるものではなく、そういう意味でも大変貴重な経験となりました。
また ML(機械学習)関連の事業と組織が急速に成長したことで従来のテキストログを扱った分析基盤に留まらず、映像や音声を扱える基盤の設計と検証を行えていることは自身のキャリアを考えても僥倖だと捉えています。
もちろん私の主戦場は今はすでに ML 基盤の設計や構築に移っています。
しかし今後もテキストログに強みを持つ分析基盤との連携は欠かせず、これまで色々な部署の方々と共に築き上げてきた関係性と培ったナレッジは大きな財産となりそうです。
組織課題
技術以外の課題としては、分析基盤と ML 基盤で取り組む際には真逆と言ってもいいほど大きく違う姿勢が求められました。
私自身の入社以前から安定運用されていた大規模システムである分析基盤と、今まさに試行錯誤を繰り返しながら設計している ML 基盤は、機能要件はもちろんのこと利用者も性能要件も全く異なるのです。
分析基盤と関連組織の特徴
10 年に渡って何 PB ものデータを蓄積しており数百名が同時に使用する分析基盤は当然ながら安定していることが求められます。
しかしその安定運用すべき分析基盤は同時に事業会社ならではスピード感で進化を続けてきており、クエリエンジンを見直し、Hive ➡️ Vertica ➡️ BigQuery と新たな技術を導入し対応してきました。
それ故に前の世代を前提としたクエリや機構が一部残ってしまい、結果複数世代のクエリエンジンを稼働させ続けなければならないなどの運用難易度を跳ね上げる課題も多く持っています。
このような事情に配慮しながら分析基盤を安定運用するためには数々の調整と慎重な準備が求められました。
ML 基盤と関連組織の特徴
一方、ML 分野の基盤や技術は今まさに全世界で試行され毎週のようにどこかで新たに生まれています。
この分野ではどれだけ早くどれだけ先進性を持って最適な基盤を提供できるかが会社全体の競争力に直結します。
見方を変えると試行錯誤のイテレーションをどれだけ早く回し、どれだけ多くの小さな失敗をしておくかが近い将来役に立つとも言えます。
またコミュニケーションに関して言えば、いかに AI リサーチャーやデータサイエンティストが増えたとは言え、それでも分析基盤の利用者と人数を比べると数分の 1 の規模で、しかもほぼ全員が同じ部に属しています。
多様な職種の数百名が使用する分析基盤と比べれば、まだまだ情報共有も行いやすい点も特徴です。
開発対象も PoC 目的のプロダクトが多くあったため、予算配分とセキュリティレベルは担保しながらも ML の環境としては「便利なものを次々に」提供すべきフェイズです。
会社としても AI リサーチャーやデータサイエンティストとしても作るべきものが毎回大きく変わるのでカッチリと形の決まった 1 つの ML 基盤を使うフェイズではありませんでした。
このように要件や取り組み方が大きく異なる 2 つの Role をずいぶんと長く兼務してきました。
ただこれは自身のコンテキストスイッチはもちろんのことチームマネジメントとしてもバランスを取ることが難しく、常に大小様々な課題を抱えていました。
私自身としてこの問題を考え続けた結果、組織変更が本質にして最大の解決という結論に達し、以降エスカレーションし続けていたように思います。
異動 1 回目
私 1 人が発した何かに限らずおそらくは色々なエスカレーションと判断があり分析基盤のクラウド化も加速する必要もあり大きな組織変更が行われました。
2019 年 10 月のことです。
それまで「AI&分析基盤」として AI システム部内で分析基盤と ML の基盤を作ってきた私は所属グループごと"IT 基盤部"という全社のインフラを一手に担う部署へ異動しました。
(私自身はそもそも組織名とクラス名には&が入らないよう構成すべきと考えていますがこの件については名称変更のタイミングを逸し続けていました)
つまり従来は図の組織でやってきましたが、

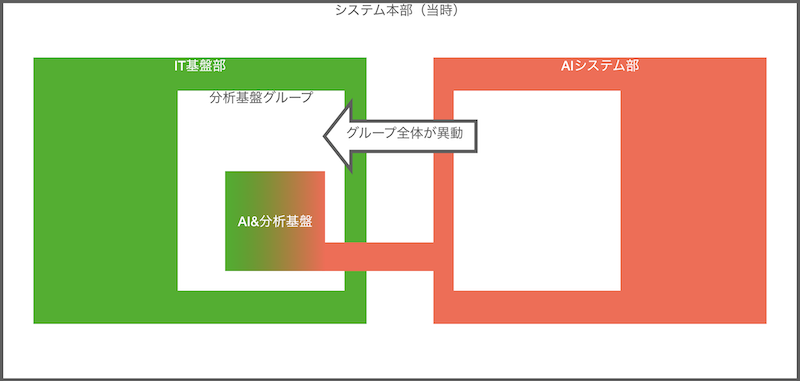
つまり DeNA で当たり前に使われている分析基盤が、全社のインフラを扱っている IT 基盤部の管掌となりました。
これは至極妥当で全社最適の観点からも、分析基盤を扱う現場の業務効率観点でも望ましい組織変更でした。
また IT 基盤部には元々頻繁にやり取りさせていただいた方も多く分析基盤に関連した業務は行いやすくなりました。
ただ私の業務比率はすでに ML の基盤に主軸を置いたものとなっており自身としては一層多くの調整が必要となりました。
実際に入社以来初めて私の残業時間が基準値を超えてしまい、各種面談やカウンセリングを設けていただくことにもなりました。
異動 2 回目
そんなわけで今度は「全社として最適化を図っていただいたおかげで多くの業務が効率化された、しかし局所では新たな課題が生まれている」と各所で課題認識がされたようです。
私自身もこの時期は考えることが増え、また相談も多くさせていただいていました。
この時期、大きな組織を取りまとめ重大な意思決定を行いながらも、私の相談にもこまめに時間を割いてくださった方々には本当に感謝しています。
しかし調整が増え業務そのものではない思考や相談も増えるということは技術タスクに割ける時間が減るということです。
やるべきこともできることも色々とある中で思うようのまとまった時間が取れない、本来出せていたはずの成果が出ない、私としてはそこに苦しんだ時期でもありました。
そんな状況がありつつも日々多くの業務をこなす中、前回の組織変更からわずか半年後に再度異動することになりました。
今後はグループ全体といった大幅な組織変更ではなく個別メンバーの異動です。
この判断と意思決定の早さには良い意味で驚きました。
再度の異動によって私は冒頭に書いた通り AI システム部に再度所属することになり、また分析基盤業務からは離れることになりました。
図に表すとこのようになります。
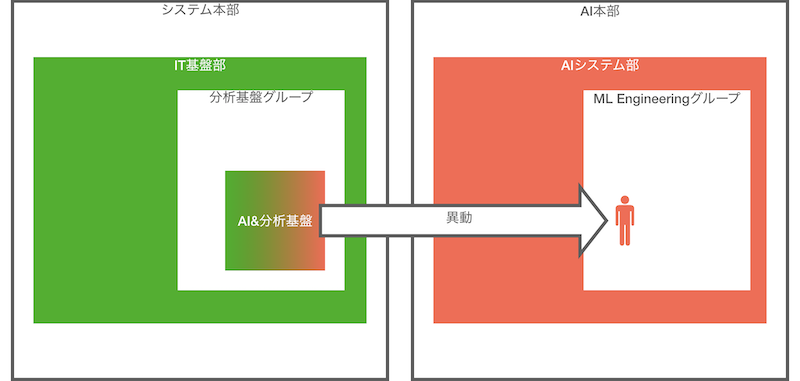
私が分析基盤業務から離れる一方で私の異動元である分析基盤グループ観点でも、いわゆる AI 分野で R&D を行うための ML 基盤業務がなくなるため、分析基盤を中心とした大規模システムの長期的な安定運用に注力できるようになります。
同時期に AI 本部も設立され ML 分野でより一層貢献できる組織が整ったことはありがたい限りです。
この一連の異動に際してはグループを越えて 2 つの部署の部長と本部長の間で多大な調整を行ってくださったものと想像します。
どこからどういう声があがったのかを私は知る由もありませんが、しかし存在していた課題が認知され実際に組織上で相当なスピード感で解決が試みられることに強く感銘を受けました。
また 2 回目の異動に際しては相当な猶予と手間をかけて調整していただけたようです。
私としてはそのおかげで引き継ぎをかなりの精度で漏れなく行うことができ、この点を特に感謝しています。
私自身はこれまで引き継ぎを受ける側になることが多く、異動退職問わずどうしても発生してしまう引き継ぎ漏れや想定しきれなかった事象に多く遭遇してきました。
引き継ぎ期間が短かったり後任が定まらないと問題が起こりがちなのですが、今回は最高の引き継ぎをしようと決意し早く広く準備を進めました。
また異動に関する人事情報が公表されてからは特に伏せることもなくなったので引き継ぎ内容を Issue として残すことにしました。
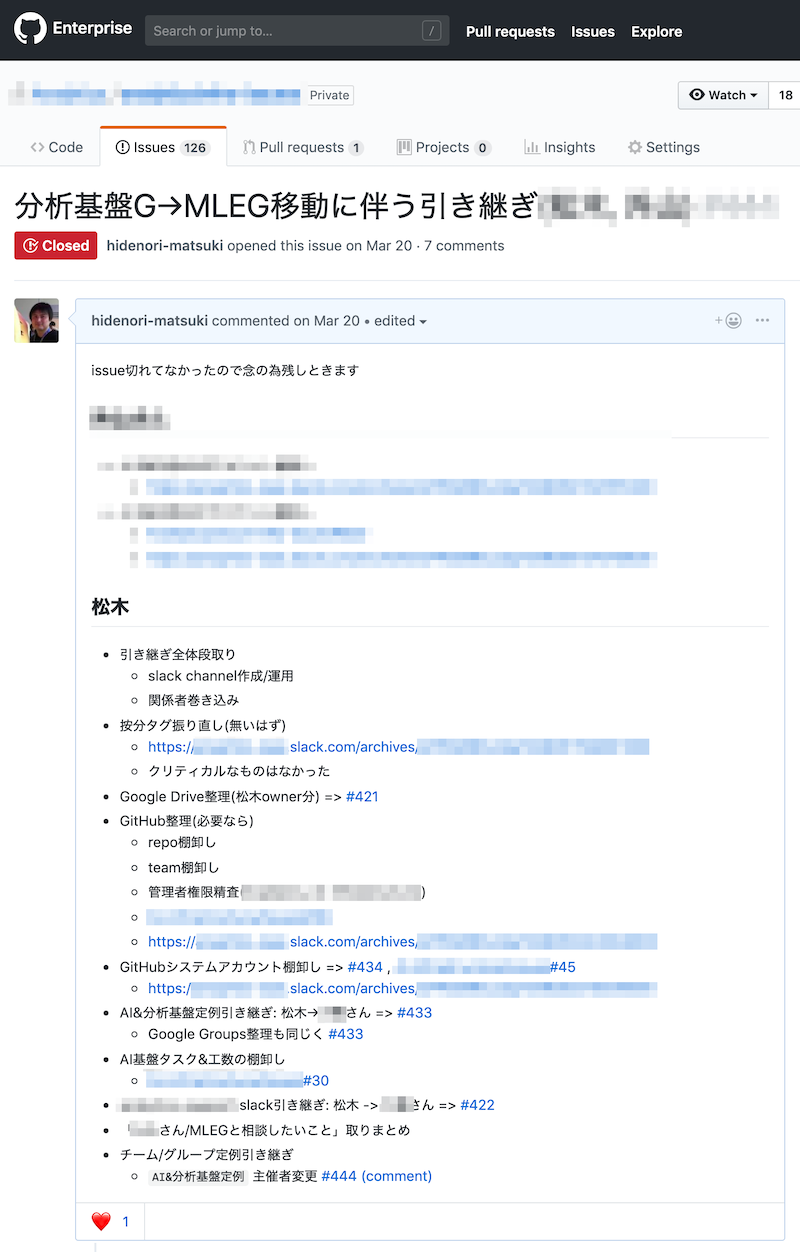
レクチャーやドキュメンテーションを引き継ぎに際して改めて行う必要がなかったこと、そして最初から後任の方と連携して動けていたおかげで大変スムーズに引き継ぎを完了できました。
引き継ぎや私の分析基盤関連の権限返却が完了し、分析基盤を使ってくださっている方に向けてサポート用の Slack 上で退任(?)の挨拶をさせていただきました。

私にとってこの経験は感慨深く、分析基盤と向き合うことは容易ではなく経験といわば勘で対処するしかないような事象に遭遇し苦労もしましたし独りで向き合わざるを得ないこともありました。
そんな思うようにいかないときでも利用者の方々は辛抱強く待ってくださったこと、少しでも情報を提供しようと協力してくださったこと、色々な感謝の気持ちがこみ上げてきました。
ML DevOps
引き継ぎを一通り段取るのは大変でしたがその分スムーズに完了したおかげで、4 月からは異動後の業務に注力できています。
また分析基盤とマネジメントの業務はなくなったので、私の役割はかなりシンプルになり動きやすくなりました。
役割を選択し集中させていただいた大きな効果の 1 つとしてミーティングが 1/3 以下に減りました。
もともとミーティングは多くない会社だと思うのですが、さらに減ったことは私にとっては嬉しい限りです。
代わりに集中して使えるようになったリソースを最高の ML 環境を提供するために注ぎ込めます。
これからは部内外の AI リサーチャーやデータサイエンティストの皆さんのために技術でできることをすべてやっていきます。
ちょうど AI 本部発足と時を同じくして CTO が就任されました。
来期より、常務執行役員 CTOとしてがんばるます。 https://t.co/PWzeRFqhnd
— nekokak (@nekokak) March 28, 2019
その新 CTO が就任に際して「 エンジニアがエンジニアリングしやすいようにやれることを全部やる 」と所信表明されたことが心に深く残っており、
私も「 ML エンジニアリングでできることを全てやるぞ 💪 」という気持ちです。
叱咤激励もいただき所属が変わっても折々に飲んだ酒の辛さと共に思い返しています。

当面半年くらいは「今の人数と事業規模を支えることができて、さらにこの先数年戦える ML 基盤」を実現させるべくどっぷり浸かるのが大きな仕事になりそうです。
ML 基盤の主要な要素の 1 つとして IaaS の考慮は欠かせませんが、これまで以上に AWS や GCP といった IaaS 各社には多大なご協力とアドバイスをいただいており、さらに日本や US でのディスカッションの機会もフルに活用させていただくつもりです。
また技術分野を広げるためのキャッチアップ機会も多様に提供されており、これらはひとえに会社環境の良さによるもので本当にありがたい限りです。
環境としてはすでに整えていただいており、あとは部や会社がこれまで以上に優れた実績を重ねられるよう貢献していくだけです。
そして私自身としてもこれまで他に投じていたリソースを集中して貢献することが回り回って自分の成長や市場価値の向上にも通じると感じています。
以上、この先もまた目まぐるしく変化するでしょうが異動を機とした振り返りでした。
なかなかこういう働き方や環境、そして各個人がどう考えどう動いているかは知る機会が気がするのでどこかで他の方の話も聞いてみたいです。